The AI Economic Paradox: Why Cheaper Inference Is Making AI More Expensive


AI inference is getting cheaper. Fast. Yet enterprise AI budgets are climbing even faster. Gartner pegs enterprise generative AI spending at $37 billion in 2025, up from $11.5 billion in 2024, a 3.2× year-over-year jump. Meanwhile, token prices keep falling by 90%.
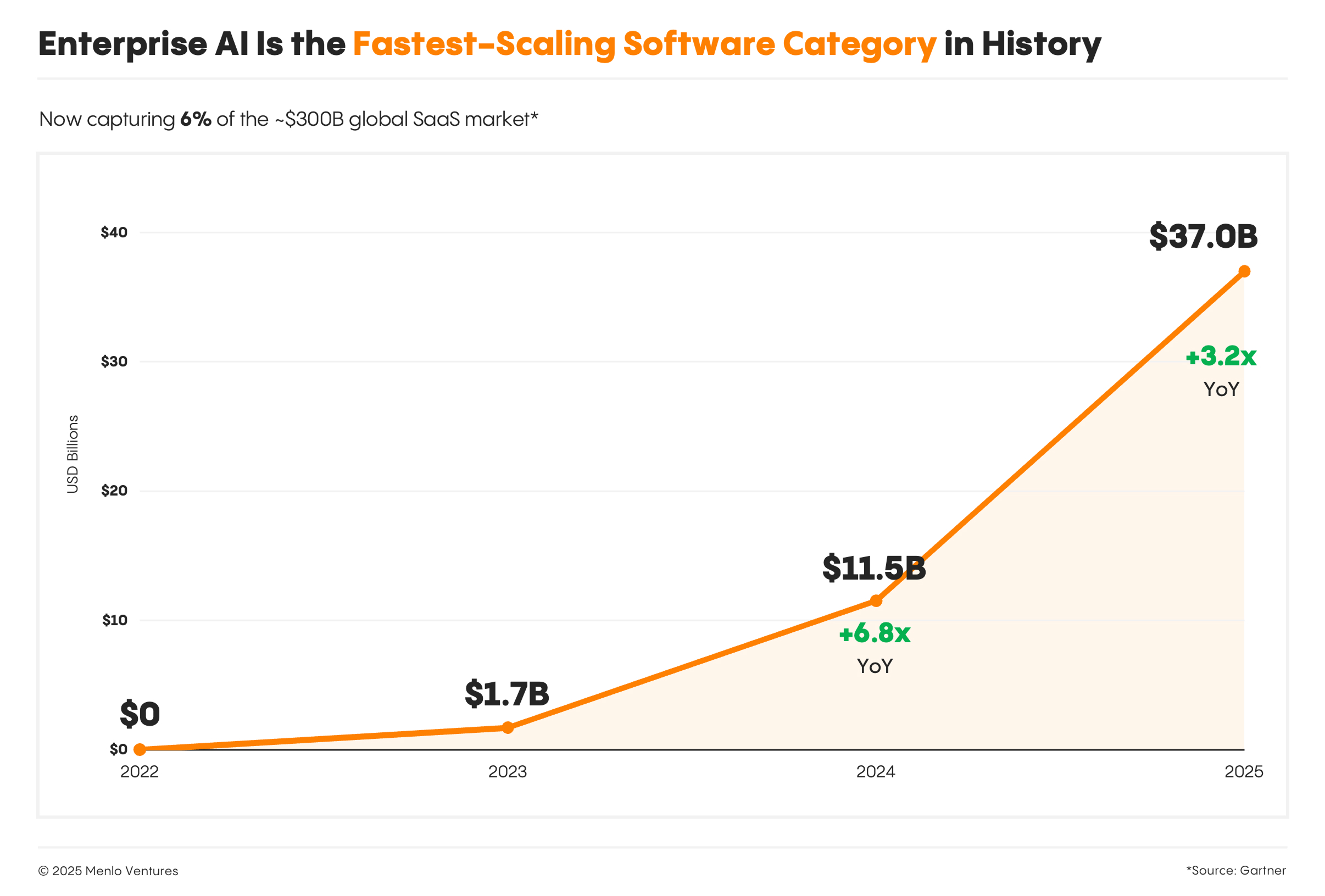
This isn't a contradiction. It's a paradox with a clear mechanism and a clear fix. Understanding it is becoming a strategic imperative for any organization deploying AI at scale.
The real risk isn't "AI costs too much." It's that AI costs are becoming unforecastable: volatile, hard to attribute, and nearly impossible to budget with confidence. Countless CTOs discovered by the end of the month the cost of AI. The underlying economics are not new, cloud computing followed the same trajectory a decade ago. But with AI, the cycle is compressed. What took cloud ten years to reveal is playing out in two or three.
The False Floor: Why "Cheap" Might Not Last
Most conversations about AI pricing treat it as a pure technology curve. Moore's Law for tokens, but on steroids. That's incomplete.
The effective price of inference is shaped by market dynamics just as much as by silicon. Crunchbase reports $202.3 billion invested into AI in 2025 — a 75% year-over-year increase across infrastructure, foundation labs, and applications. That scale of capital sustains market-share-driven behavior: aggressive pricing, bundling, and packaging designed to capture adoption, not necessarily to reflect sustainable unit economics.
Profitability in the AI provider market is more nuanced than it appears. Epoch AI offers a useful decomposition: a model can show decent gross margins (~50% when subtracting inference compute) while still being loss-making at an operating or lifecycle level. When you factor in staffing, sales, and the reality that model tenures are short , meaning R&D may not be fully recouped during a model's commercial lifetime, the picture changes. This is the "GPT-5 bundle" scenario Epoch describes: plausible gross margin, questionable operating margin, uncertain lifecycle return.
Why does this matter? Because pricing regimes can shift through repricing, packaging changes, renegotiations, or provider consolidation. Today's cheap inference is a tailwind, not a structural assumption.
The Cloud Déjà Vu: Same Economics, Faster Clock
The economics of AI adoption are not novel. They are a near-exact replay of cloud computing economics, running on a compressed timeline.
Cloud adoption followed a well-documented arc: early agility gains attracted rapid adoption, usage expanded because unit costs felt low, then cost visibility arrived late — usually when the business was already deeply committed and re-architecture was expensive. Andreessen Horowitz described the endgame: as companies scale and growth slows, cloud's pressure on margins can outweigh its benefits. Reversing cost structure later requires re-architecture and time.
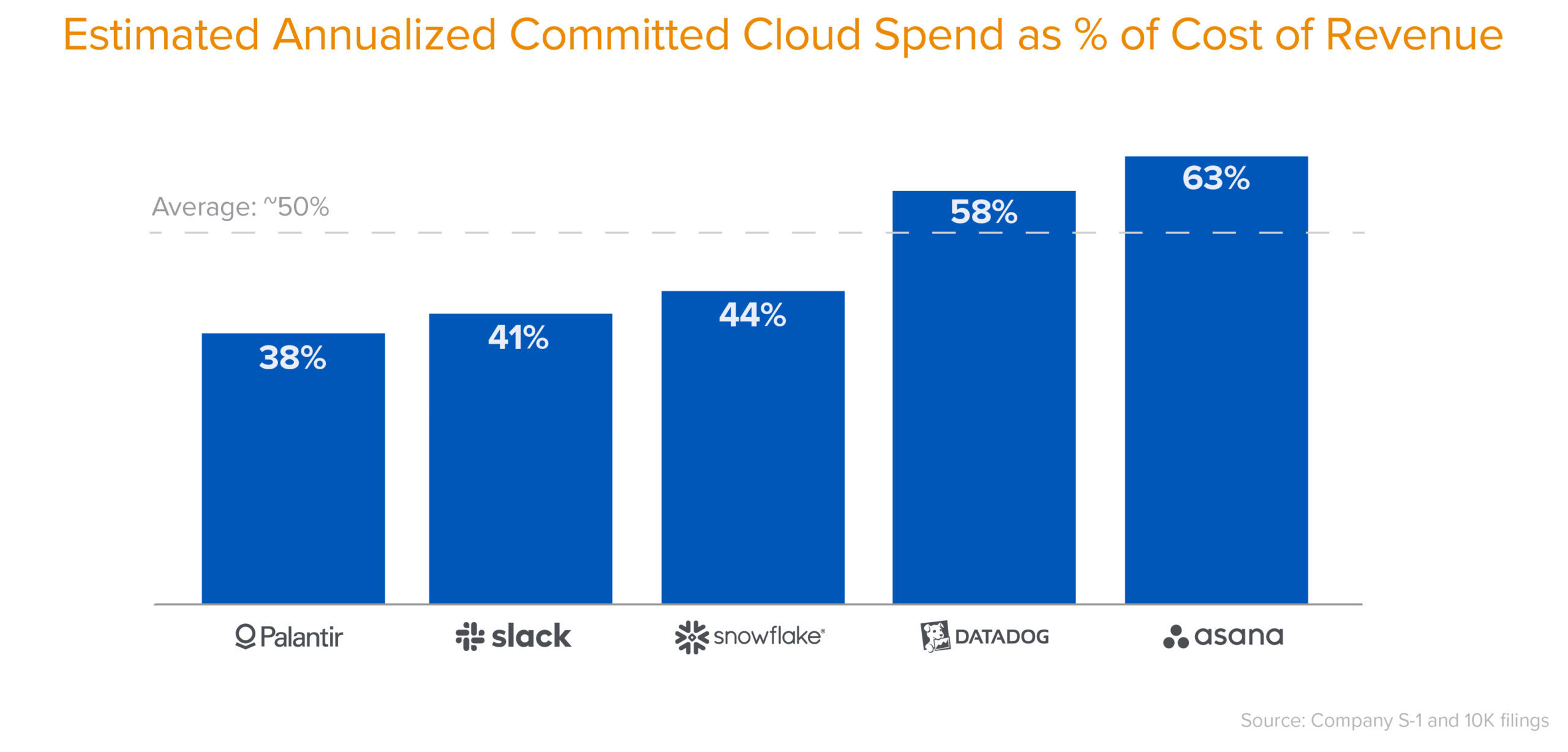
The structural parallels to AI are striking. In both cases, low unit costs encourage elastic demand, organizations don't just do existing work cheaper, they expand into new use cases they wouldn't have attempted at higher prices. In both cases, adoption spreads across teams organically, often without centralized visibility. In both cases, the largest cost drivers turn out to be architectural, not volumetric. They emerge from how systems are built, not just how many users they serve. And in both cases, the hardest costs to manage are the ones nobody anticipated because they weren't directly visible in any single invoice line.
The difference is speed. Cloud's cost reckoning took roughly a decade, from early adoption in the late 2000s to the FinOps movement of the late 2010s. AI is compressing that cycle dramatically. Usage expands faster because unit costs fall faster. "Shadow" adoption proliferates across teams from a product manager spins up an agent here, to an engineer adds a summarization step there. And the heaviest cost drivers emerge not from user growth, but from inside workflows like agents, retries, retrieval bloat, prompt drift, that nobody budgeted for because nobody knew they existed until the invoice arrived.
Cloud's lesson wasn't "cloud is bad." It was: infrastructure needs an operating model before cost becomes a board-level surprise. AI needs the same discipline but significantly sooner.
The End-of-Month AI Shock
Here's how AI costs become unforecastable in practice.
Visibility is fragmented. AI usage is distributed across products, internal tools, pilots, and multiple vendors. Invoices don't tell you which workflows got more expensive or why. Agentic workflows multiply requests. Agents aren't endpoints. One user action can trigger planning, retrieval, tool calls, retries, fallbacks, and evaluation steps. These patterns create multiplicative cost, not linear cost. A support ticket that triggers 5 model calls in staging can trigger 50 in production when threads are longer, tools fail, and prompts are ambiguous.
Reliability behaviors compound spend. When latency or errors rise, many systems respond by retrying, falling back, or "thinking longer." This converts operational instability into spend spikes silently.
Consider a typical scenario: a support org ships "Agent Assist." Staging looks clean — a handful of calls per ticket. Production is messier. Longer threads, tool failures, ambiguity. The agent retries, loops through tools, expands retrieval. A prompt revision increases context size. Calls per ticket climb from single digits to tens, occasionally hundreds. Nobody notices until the month closes because costs aren't attributable at the workflow level and there's no execution-time ceiling. Finance flags the overage. Engineering kills the feature. The org learns the wrong lesson: "Agents are too expensive."
The real lesson: the system lacked real-time bounds and cost explainability.
Prices Fall Fast — But Unevenly
Here's the good news, with a caveat. Epoch AI shows inference prices have fallen dramatically but unevenly across tasks and performance thresholds. The range is striking: 9× to 900× per year, depending on the benchmark. For reaching GPT-4-level performance on PhD-level science questions (GPQA Diamond), the cost dropped roughly 40× per year.
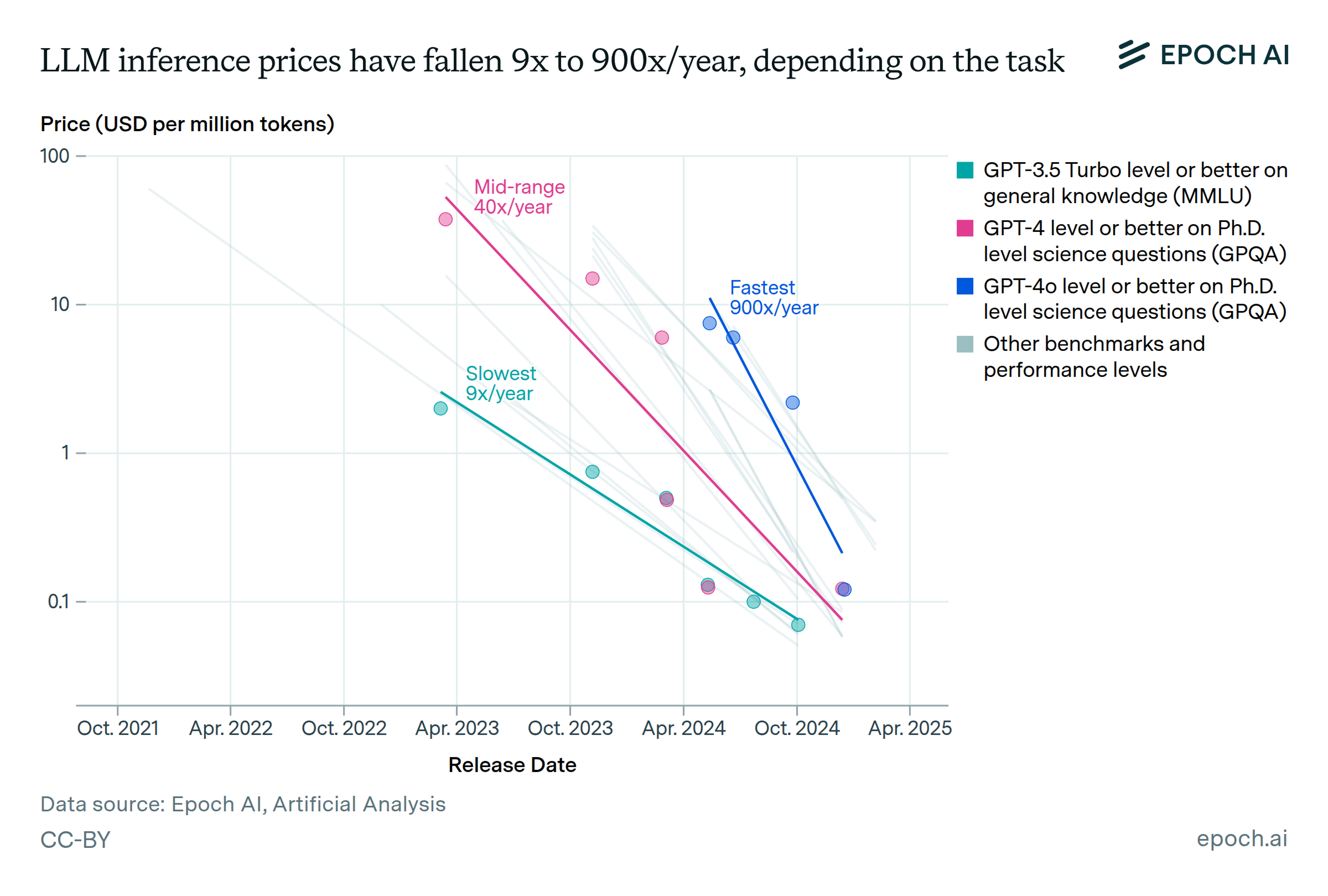
Artificial Analysis tracks this moving frontier in real time — model intelligence, speed, latency, and price across providers. It's a useful resource for anyone making routing or procurement decisions. The implication is important: you can't forecast AI costs by locking in a unit price and projecting forward. Models change. Providers change. The quality-speed-price frontier shifts constantly. Forecasting must rely not on stable unit prices, but on bounded system behavior.
Why SaaS Math Breaks
Traditional SaaS budgeting, users x subscription, doesn't work for AI because AI workloads have characteristics SaaS doesn't: Context sizes are long-tailed: you generate a small percentage of requests that consume disproportionate tokens. Agent behavior is heavy-tailed too, with most interactions staying cheap while some explode in cost. Retries and fallbacks amplify spend in ways that are hard to predict, and prompts and retrieval policies drift over time as teams iterate and systems accumulate context.
The practical alternative is to think in cost envelopes with variance bounds rather than point estimates. That means defining expected ranges per workflow, classifying workloads by request shape, and setting hard ceilings at execution time so that tail cases can't dominate the month.
Finance doesn't need perfect predictions. They need confidence that the system cannot exceed bounded limits without an explicit policy change. That's the mental model shift: from "how much will AI cost?" to "what's the maximum it can cost without someone deciding it should?"
Finance doesn't need perfect predictions. They need confidence that the system cannot exceed bounded limits without an explicit policy change. That's the mental model shift: from "how much will AI cost?" to "what's the maximum it can cost without someone deciding it should?"
Compression: The Most Underrated Lever
The most effective scalable lever for forecastable cost isn't negotiating unit price. It's reducing billed tokens and billed steps. That requires compression at two layers.
Prompt-layer compression shrinks what you send per request: instructions, conversation history, retrieved context. This means pruning irrelevant turns, capping top-k retrieval, enforcing relevance thresholds, deduplicating passages, and rewriting large context into compact, structured state — facts, constraints, and open questions rather than narrative summaries.
Context-layer compression shrinks what your system produces around the request. This is the overlooked layer. Production stacks add substantial tokens and calls outside the user prompt: large tool schemas repeated every call, verbose agent scaffolding, planning templates, intermediate planner-router-verifier-rewriter chains that multiply tokens and steps, retry amplification that re-sends the same large context, and prompts demanding verbose "explain your work" output when it isn't needed for correctness.
Context-layer compression means sending only the tools needed for the next step, shortening system policies, invoking multi-step patterns only when uncertainty is high, enforcing retry budgets, and avoiding verbose reasoning text by default.
The central challenge is compressing while preserving semantic similarity. Remove too many tokens and you remove meaning.
The Operating Model: Four Disciplines
At production scale, the question isn't "which model is best?" It's: can we keep cost forecastable while preserving quality and reliability?
- Routing discipline. Route by workload class — commodity tasks to smaller, cheaper models; reasoning-heavy tasks to larger ones. Set explicit cost and latency ceilings per class. Define fallback behavior under provider instability. Prevent ad-hoc model drift across teams, which is a major and underappreciated source of forecast variance.
- Compression discipline. Treat token volume and step inflation as first-class cost drivers, not afterthoughts. Apply prompt-layer and context-layer compression systematically across all production workflows. Measure semantic similarity to ensure compression doesn't degrade meaning and trigger the overcompensation cycle that makes costs unbounded again.
- Real-time constraints. Don't wait for the invoice. Set hard caps on wall-time, call count, tool depth, and recursion depth. Enforce retry budgets, change strategy rather than repeat the same failing request. Apply spend ceilings per workflow and per customer at execution time. Alert on amplification events like retry storms and tool loops.
- Cost explainability. Trace execution steps across multi-step workflows. Link cost shifts to changes — which prompt version, which config, which model. Attribute spend by workflow and owner so drift is actionable, not just visible.
Add evaluation where it protects cost controls: validate that degradation modes remain acceptable. Prevent cost ceilings from silently breaking core outcomes.
Inference Economics Is the New Cloud Economics
AI is becoming infrastructure. And infrastructure, we've learned the hard way, requires an operating model.
The history of cloud computing taught us that the most dangerous moment isn't when costs are high. It's when costs are low enough to encourage unrestricted adoption, but invisible enough that nobody tracks the compounding. AI is entering that exact phase, significantly faster, with more moving parts, and with cost drivers that are genuinely harder to observe than cloud ever was.
The organizations that navigate this well won't be the ones who predicted token prices correctly. They'll be the ones who made price predictions irrelevant by designing systems where costs are bounded, explainable, and forecastable regardless of what happens underneath.
The paradox resolves not by predicting the price of AI, but by engineering the predictability of the spend.
--
Sources:
- Menlo Ventures (2025 State of Generative AI in the Enterprise),
- Crunchbase (AI Funding Trends 2025),
- Andreessen Horowitz (The Cost of Cloud),
- Epoch AI (LLM Inference Prices; AI Profitability Analysis),
- Artificial Analysis (AI Model Trends & Benchmarks).