Token Compression
When enabled, token compression runs at the edge before your request reaches LLM providers. This can reduce input tokens by up to 50% for common workloads like RAG pipelines, long document analysis, and multi-turn conversations.Up to 50% token reduction
Lower latency with smaller payloads
Real-time savings tracking
How It Works
Token compression analyzes your prompt structure to:- Remove redundant context without losing semantic meaning
- Optimize RAG document formatting for better compression ratios
- Preserve critical instructions and few-shot examples
- Maintain output quality while reducing input costs
Multiple Compression Engines
Edgee offers multiple compression engines optimized for different workloads:
Agentic Token Compression
Combines several strategies: semantic analysis, lossless tool compression, JSON crusher, and cache optimizer… works with all models.

Claude Token Compression (Beta)
Provides fully lossless compression for Claude Code.
Edge-First Architecture
Traditional AI gateways route all traffic through centralized servers. Edgee processes requests at the edge, closest to your application or user.< 10ms processing overhead
100+ edge locations
Privacy controls built-in
How It Works
Global Network
Powered by Fastly and AWS, our network spans six continents: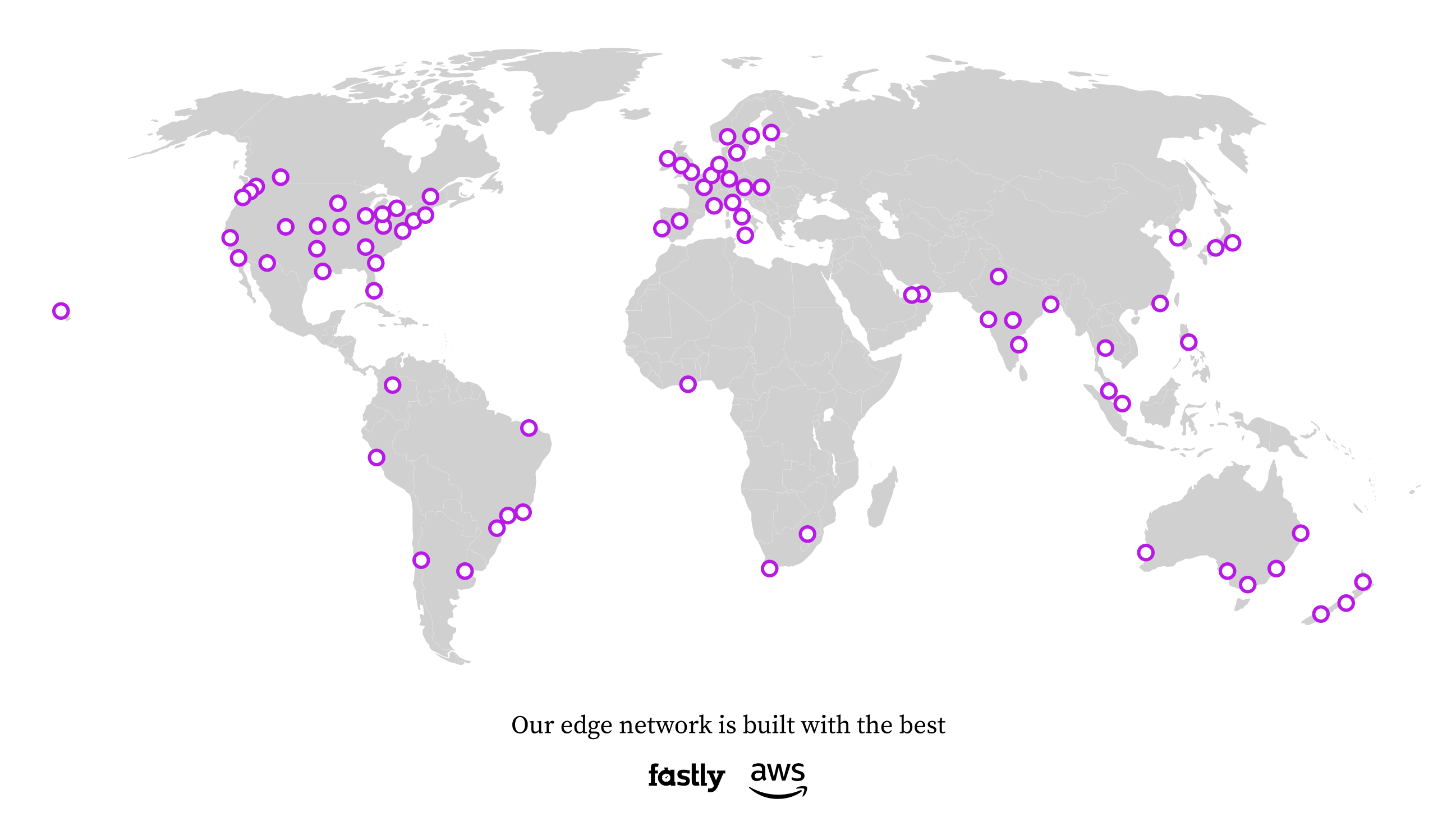
Requests are automatically routed to the nearest PoP via Anycast. No configuration needed.
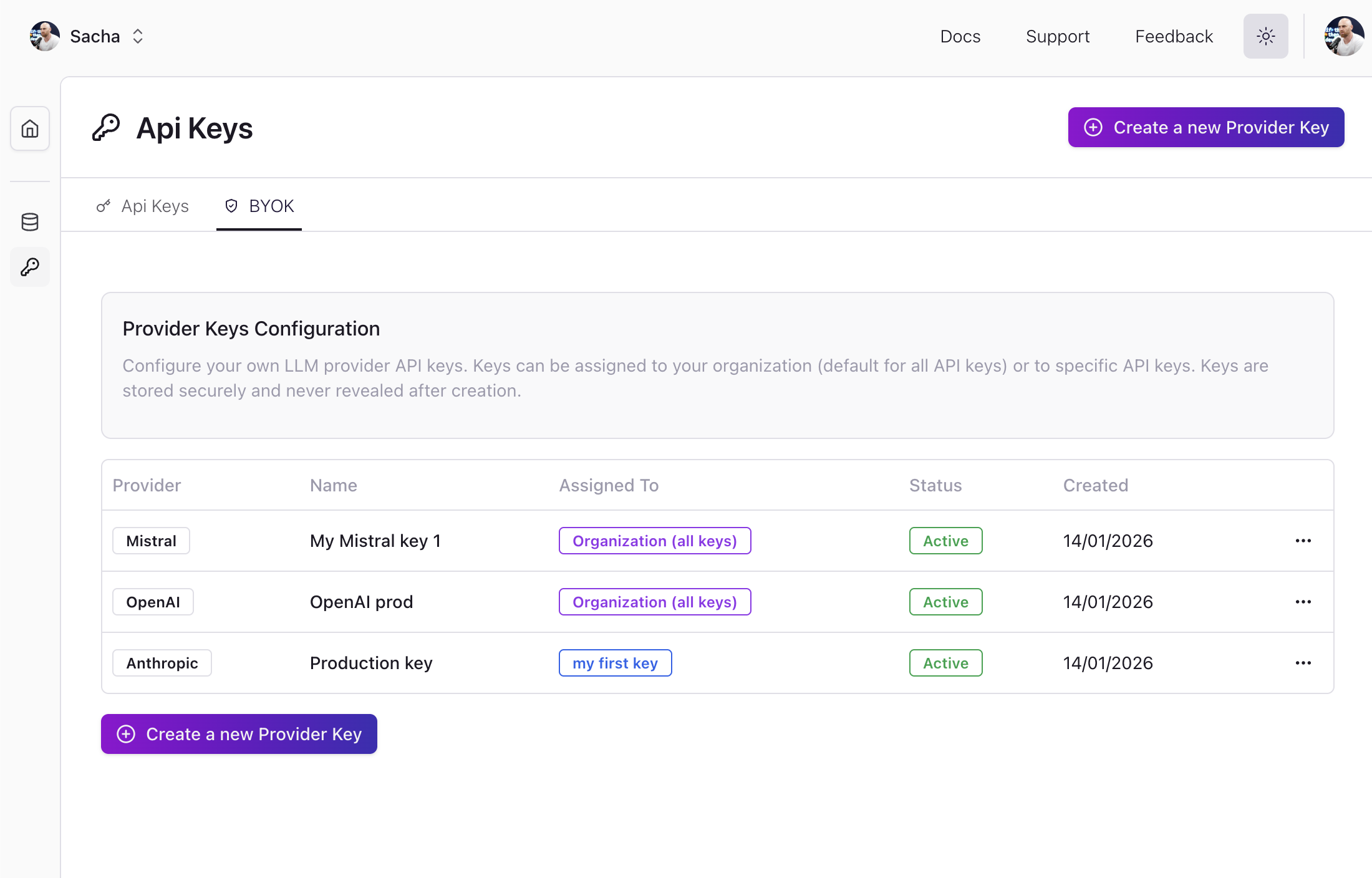
One Key, All Models
With a single Edgee API key, you get instant access to every supported model; OpenAI, Anthropic, Google, Mistral, and more. No need to manage multiple provider accounts or juggle API keys:Bring Your Own Keys
Need more control? Use your existing provider API keys alongside Edgee. This gives you direct billing relationships, access to custom fine-tuned models, and the ability to use provider-specific features. You can mix both approaches—use Edgee’s unified access for some providers and your own keys for others.