Retry and Fallback: How Edgee Keeps Your LLM Requests Reliable


Imagine running LLM-powered features, and suddenly 10% of provider API calls start failing. Your users see errors, whether due to capacity issues or regional degradation.
If your application calls the provider directly, those failures are reflected in your users' experience. If your requests go through Edgee, most of them succeed on the first fallback attempt: no code changes, no on-call pages, no manual intervention.
Before exploring the technical details, let's look at how Edgee's retry-and-fallback system is designed, why each component matters, and what you can expect when running in real-world environments.
The problem with naive retry logic
The simplest retry strategy is "if it fails, try again." It works surprisingly often, since many HTTP failures are transient. But in the context of LLM APIs, simple retries have real problems:
- Not all errors are transient. A malformed request will fail every time you retry it. A 401 means your key is invalid. Unthinkingly retrying wastes time and quota.
- Retrying the same provider isn't always useful. If a provider is returning 503s because of a capacity issue, hitting it again a second later is unlikely to help. You need a different provider.
- Streaming complicates everything. If you've already started sending chunks to the client and the provider fails mid-stream, you can't just transparently switch to another provider. The client has already received partial data.
- You need visibility. If 8% of your requests are silently retrying, you want to know. Silent retries that "just work" are great for users, but engineering teams need to see what's happening under the hood.
Edgee brings a comprehensive solution to these issues. It combines error classification, provider-level fallback with scoring, and full observability into a single cohesive system, directly addressing the pain points described above.
How errors are classified
When a provider request fails, Edgee doesn't just look at "success or failure." It classifies the error into one of three categories, and each category triggers a different recovery behaviour:
| Triggers | Action | Behaviour |
|---|---|---|
| 5xx, 429 | Retry, then fallback | Retries the same provider once. If the retry also fails, moves to the next provider in the fallback list. |
| 408, 504, timeouts, SSE failures | Immediate fallback | Skips the retry and moves straight to the next provider — retrying the same one is unlikely to help. |
| 4xx, invalid key, bad request | Return the error | Returns the error to the caller immediately. The problem is on the client side; no retry or fallback will fix it. |
This classification matters because it prevents two common failure modes: wasting time retrying errors that will never succeed, and giving up too early on errors that a different provider could handle.
The execution loop
With error classification in place, the actual execution follows a straightforward loop:
-
Score and order providers. Before the first request, Edgee scores all available providers for the requested model and sorts them by score (more on scoring below). The highest-scoring provider becomes the primary.
-
Try the primary provider. Send the request. If it succeeds, return the response. Done.
-
If it fails, classify the error. Based on the classification:
- Retry then fallback: retry the primary once. If the retry also fails, move to step 4.
- Immediate fallback: skip directly to step 4.
- Return error: stop and return the error to the client.
-
Try the next provider in the list. Fallback providers get a single attempt each, with no retries. If it succeeds, return the response. If it fails, classify and continue to the next provider.
-
If all providers are exhausted, return the last error along with details about every provider that was attempted.
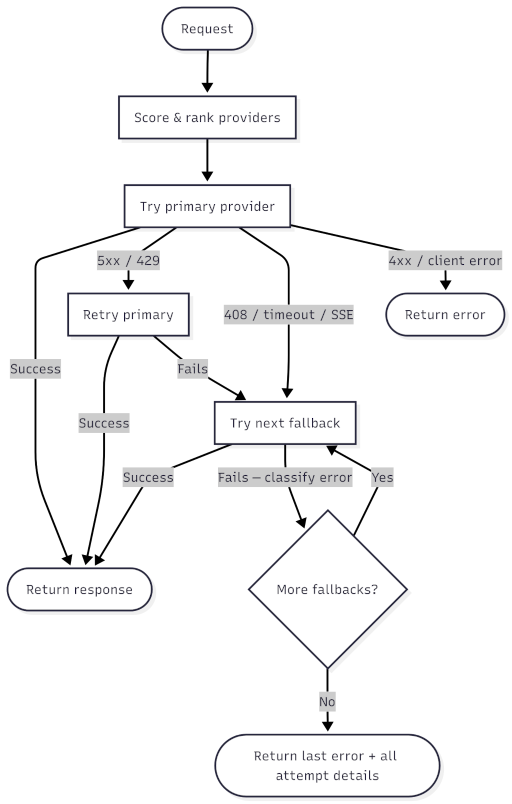
The primary provider gets at most two attempts (initial + one retry). Every fallback provider gets exactly one attempt. This keeps the total latency bounded. You won't see a request bounce through five retries across three providers.
Provider scoring: choosing the best fallback order
The fallback order isn't random. Before each request, Edgee scores every provider that supports the requested model, using real-time metrics collected from recent traffic.
Providers are ranked by their recent success rate. A provider that has been returning errors will naturally sink in the ranking, while healthy providers rise to the top. The system adapts continuously: a provider recovering from an incident will gradually regain its position as its success rate improves.
A few design details make this scoring robust:
- Datacenter-qualified metrics. Provider performance can vary by region. A provider that's fast in US-East might be slow in EU-West. Metrics are stored per datacenter, so scoring reflects the performance your users actually experience.
- Fail-open behaviour. If metrics aren't available (new provider, store hiccup, cold start), all providers default to a score of 1.0. The system never refuses to try a provider just because it lacks historical data.
- Tie-breaking by shuffle. When multiple providers have the same score, their order is randomised. This provides natural load distribution across equally healthy providers.
- Disabled provider filtering. Providers can be operationally disabled through metrics. When a provider is marked as disabled, it's filtered out of the candidate list. But if all providers are disabled, the filter is skipped entirely as a safety valve, so requests can still be served.
The streaming edge case
Streaming responses introduce a constraint that doesn't exist in standard request-response flows: once the first chunk has been sent to the client, Edgee can no longer retry or fall back transparently.
Think about it from the client's perspective. If you're receiving a streamed response and the provider fails after sending 200 tokens, there's no way to switch to a different provider seamlessly. The new provider would have to start from scratch, and the client would see duplicate or inconsistent content.
So Edgee draws a clear line:
- Before the first chunk: full retry and fallback behaviour applies, exactly as described above. If the provider fails during connection setup or before any data flows, Edgee retries or falls back to a normal state.
- After the first chunk: the response is committed. If the provider fails mid-stream, the error is surfaced to the client—no silent switchover.
When a retry is possible (before the first chunk), the stream state is fully reset before attempting again. This ensures no partial data leaks between attempts.
This is a deliberate trade-off. In practice, most provider failures happen at connection time or during the initial processing phase, before any chunks are sent. The window where a mid-stream failure could occur is relatively small, and attempting to hide it would create worse problems than surfacing it.
BYOK-aware routing
Many organisations use Bring Your Own Key (BYOK): they provide their own API keys for specific providers, keeping their direct billing relationship while using Edgee for routing and observability.
The retry-and-fallback system is BYOK-aware. When building the provider candidate list, Edgee checks whether the request's API key includes provider-specific credentials:
- If BYOK credentials exist, providers matching those credentials are preferred. This ensures your own keys are used first, and Edgee-managed providers serve as a fallback.
- If the organisation has zero remaining credits on the Edgee platform, only BYOK providers are eligible. Edgee won't silently fall back to platform-managed providers and incur charges the organisation can't cover.
This means BYOK users get the same retry and fallback resilience as platform-managed users. Their own providers are tried first, with Edgee providers available as a safety net.
Full observability into failed attempts
Silent resilience is great for end users, but engineering teams need to see what's happening. That's why every failed attempt, whether it was retried, fell back, or ultimately succeeded on a different provider, is recorded as a separate entry in Edgee's usage tracking.
Each failed attempt records:
- Which provider was tried
- What error occurred (unavailable, timeout, rate limit, etc.)
- How long the attempt took before failing
These are logged as zero-token usage entries. They didn't produce a billable response, but they're fully visible in your usage data. This gives you a clear picture of provider reliability over time, without any blind spots.
To avoid noise, the system also prevents double-logging: when the final result is itself an error, the last failed attempt (which represents the same failure) is skipped.
Additionally, the response includes headers that tell you what happened:
X-Edgee-Provider: which provider ultimately served the requestX-Edgee-Fallback-Used: present (with value1) if the response came from a fallback provider rather than the primary
These headers make it straightforward to build alerting on fallback rates, track provider reliability from the client side, or debug a specific request.
Putting it all together
Here's what a typical failure-and-recovery sequence looks like in practice:
- Your application sends a chat completion request to Edgee.
- Edgee scores providers: Provider A (98% success rate) is primary, Provider B (95%) is first fallback, Provider C (92%) is second.
- Provider A returns a 503. The error is classified as retry then fallback.
- Edgee retries Provider A. Another 503.
- Edgee falls back to Provider B. Success. The response is returned to your application.
- Your application receives the response with headers
X-Edgee-Provider: provider-bandX-Edgee-Fallback-Used: 1. - Two failed attempt entries are recorded (Provider A, attempts 1 and 2), plus one successful entry (Provider B).
- Provider A's success rate drops slightly, affecting its score for future requests.
From your application's perspective, the request succeeded. From your observability dashboard, you can see exactly what happened and track whether Provider A's issues are a blip or a trend.
The goal of the retry and fallback system is straightforward: your requests should succeed whenever a working provider exists, and you should have full visibility into when and why Edgee had to work around a failure.
If you're running LLM calls in production and want this kind of resilience without building it yourself:
- Get started: edgee.ai
- Read the docs: docs.edgee.ai